Genie: An Open Box Counterfactual Policy Estimator for Optimizing Sponsored Search Marketplace
In this paper, we propose an offline counterfactual policy estimation framework called Genie to optimize Sponsored Search Marketplace. Genie employs an open box simulation engine with click calibration model to compute the KPI impact of any modification to the system. From the experimental results on Bing traffic, we showed that Genie performs better than existing observational approaches that employs randomized experiments for traffic slices that have frequent policy updates. We also show that Genie can be used to tune completely new policies efficiently without creating risky randomized experiments due to cold start problem. As time of today, Genie hosts more than 10000 optimization jobs yearly which runs more than 30 Million processing node hours of big data jobs for Bing Ads. For the last 3 years, Genie has been proven to be the one of the major platforms to optimize Bing Ads Marketplace due to its reliability under frequent policy changes and its efficiency to minimize risks in real experiments.
The What, the Why, and the How of Artificial Explanations in Automated Decision-Making
The increasing incorporation of Artificial Intelligence in the form of automated systems into decision-making procedures highlights not only the importance of decision theory for automated systems but also the need for these decision procedures to be explainable to the people involved in them. Traditional realist accounts of explanation, wherein explanation is a relation that holds (or does not hold) eternally between an explanans and an explanandum, are not adequate to account for the notion of explanation required for artificial decision procedures. We offer an alternative account of explanation as used in the context of automated decision-making that makes explanation an epistemic phenomenon, and one that is dependent on context. This account of explanation better accounts for the way that we talk about, and use, explanations and derived concepts, such as `explanatory power’, and also allows us to differentiate between reasons or causes on the one hand, which do not need to have an epistemic aspect, and explanations on the other, which do have such an aspect. Against this theoretical backdrop we then review existing approaches to explanation in Artificial Intelligence and Machine Learning, and suggest desiderata which truly explainable decision systems should fulfill.
Increasing Trust in AI Services through Supplier’s Declarations of Conformity
The accuracy and reliability of machine learning algorithms are an important concern for suppliers of artificial intelligence (AI) services, but considerations beyond accuracy, such as safety, security, and provenance, are also critical elements to engender consumers’ trust in a service. In this paper, we propose a supplier’s declaration of conformity (SDoC) for AI services to help increase trust in AI services. An SDoC is a transparent, standardized, but often not legally required, document used in many industries and sectors to describe the lineage of a product along with the safety and performance testing it has undergone. We envision an SDoC for AI services to contain purpose, performance, safety, security, and provenance information to be completed and voluntarily released by AI service providers for examination by consumers. Importantly, it conveys product-level rather than component-level functional testing. We suggest a set of declaration items tailored to AI and provide examples for two fictitious AI services.
Catastrophic Importance of Catastrophic Forgetting
This paper describes some of the possibilities of artificial neural networks that open up after solving the problem of catastrophic forgetting. A simple model and reinforcement learning applications of existing methods are also proposed.
Vicious Circle Principle and Logic Programs with Aggregates
The paper presents a knowledge representation language

which extends ASP with aggregates. The goal is to have a language based on simple syntax and clear intuitive and mathematical semantics. We give some properties of
, an algorithm for computing its answer sets, and comparison with other approaches.
Isometric Transformation Invariant Graph-based Deep Neural Network
Learning transformation invariant representations of visual data is an important problem in computer vision. Deep convolutional networks have demonstrated remarkable results for image and video classification tasks. However, they have achieved only limited success in the classification of images that undergo geometric transformations. In this work we present a novel Transformation Invariant Graph-based Network (TIGraNet), which learns graph-based features that are inherently invariant to isometric transformations such as rotation and translation of input images. In particular, images are represented as signals on graphs, which permits to replace classical convolution and pooling layers in deep networks with graph spectral convolution and dynamic graph pooling layers that together contribute to invariance to isometric transformation. Our experiments show high performance on rotated and translated images from the test set compared to classical architectures that are very sensitive to transformations in the data. The inherent invariance properties of our framework provide key advantages, such as increased resiliency to data variability and sustained performance with limited training sets. Our code is available online.
CoBaR: Confidence-Based Recommender
Neighborhood-based collaborative filtering algorithms usually adopt a fixed neighborhood size for every user or item, although groups of users or items may have different lengths depending on users’ preferences. In this paper, we propose an extension to a non-personalized recommender based on confidence intervals and hierarchical clustering to generate groups of users with optimal sizes. The evaluation shows that the proposed technique outperformed the traditional recommender algorithms in four publicly available datasets.
Multinomial Models with Linear Inequality Constraints: Overview and Improvements of Computational Methods for Bayesian Inference
Many psychological theories can be operationalized as linear inequality constraints on the parameters of multinomial distributions (e.g., discrete choice analysis). These constraints can be described in two equivalent ways: 1) as the solution set to a system of linear inequalities and 2) as the convex hull of a set of extremal points (vertices). For both representations, we describe a general Gibbs sampler for drawing posterior samples in order to carry out Bayesian analyses. We also summarize alternative sampling methods for estimating Bayes factors for these model representations using the encompassing Bayes factor method. We introduce the R package multinomineq, which provides an easily-accessible interface to a computationally efficient C++ implementation of these techniques.
Polar Convolution
The Moreau envelope is one of the key convexity-preserving functional operations in convex analysis, and it is central to the development and analysis of many approaches for solving convex optimization problems. This paper develops the theory for a parallel convolution operation, called the polar envelope, specialized to gauge functions. We show that many important properties of the Moreau envelope and the proximal map are mirrored by the polar envelope and its corresponding proximal map. These properties include smoothness of the envelope function, uniqueness and continuity of the proximal map, a role in duality and in the construction of algorithms for gauge optimization. We thus establish a suite of tools with which to build algorithms for this family of optimization problems.
Keyphrase Generation with Correlation Constraints
In this paper, we study automatic keyphrase generation. Although conventional approaches to this task show promising results, they neglect correlation among keyphrases, resulting in duplication and coverage issues. To solve these problems, we propose a new sequence-to-sequence architecture for keyphrase generation named CorrRNN, which captures correlation among multiple keyphrases in two ways. First, we employ a coverage vector to indicate whether the word in the source document has been summarized by previous phrases to improve the coverage for keyphrases. Second, preceding phrases are taken into account to eliminate duplicate phrases and improve result coherence. Experiment results show that our model significantly outperforms the state-of-the-art method on benchmark datasets in terms of both accuracy and diversity.
Neural Latent Extractive Document Summarization
Extractive summarization models need sentence level labels, which are usually created with rule-based methods since most summarization datasets only have document summary pairs. These labels might be suboptimal. We propose a latent variable extractive model, where sentences are viewed as latent variables and sentences with activated variables are used to infer gold summaries. During training, the loss can come directly from gold summaries. Experiments on CNN/Dailymail dataset show our latent extractive model outperforms a strong extractive baseline trained on rule-based labels and also performs competitively with several recent models.
Model Interpretation: A Unified Derivative-based Framework for Nonparametric Regression and Supervised Machine Learning
Interpreting a nonparametric regression model with many predictors is known to be a challenging problem. There has been renewed interest in this topic due to the extensive use of machine learning algorithms and the difficulty in understanding and explaining their input-output relationships. This paper develops a unified framework using a derivative-based approach for existing tools in the literature, including the partial-dependence plots, marginal plots and accumulated effects plots. It proposes a new interpretation technique called the accumulated total derivative effects plot and demonstrates how its components can be used to develop extensive insights in complex regression models with correlated predictors. The techniques are illustrated through simulation results.
Neural Architecture Optimization
Automatic neural architecture design has shown its potential in discovering powerful neural network architectures. Existing methods, no matter based on reinforcement learning or evolutionary algorithms (EA), conduct architecture search in a discrete space, which is highly inefficient. In this paper, we propose a simple and efficient method to automatic neural architecture design based on continuous optimization. We call this new approach neural architecture optimization (NAO). There are three key components in our proposed approach: (1) An encoder embeds/maps neural network architectures into a continuous space. (2) A predictor takes the continuous representation of a network as input and predicts its accuracy. (3) A decoder maps a continuous representation of a network back to its architecture. The performance predictor and the encoder enable us to perform gradient based optimization in the continuous space to find the embedding of a new architecture with potentially better accuracy. Such a better embedding is then decoded to a network by the decoder. Experiments show that the architecture discovered by our method is very competitive for image classification task on CIFAR-10 and language modeling task on PTB, outperforming or on par with the best results of previous architecture search methods with a significantly reduction of computational resources. Specifically we obtain
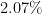
test set error rate for CIFAR-10 image classification task and

test set perplexity of PTB language modeling task. The best discovered architectures on both tasks are successfully transferred to other tasks such as CIFAR-100 and WikiText-2.
A Survey of Modern Object Detection Literature using Deep Learning
Object detection is the identification of an object in the image along with its localisation and classification. It has wide spread applications and is a critical component for vision based software systems. This paper seeks to perform a rigorous survey of modern object detection algorithms that use deep learning. As part of the survey, the topics explored include various algorithms, quality metrics, speed/size trade offs and training methodologies. This paper focuses on the two types of object detection algorithms- the SSD class of single step detectors and the Faster R-CNN class of two step detectors. Techniques to construct detectors that are portable and fast on low powered devices are also addressed by exploring new lightweight convolutional base architectures. Ultimately, a rigorous review of the strengths and weaknesses of each detector leads us to the present state of the art.
k-meansNet: When k-means Meets Differentiable Programming
In this paper, we study how to make clustering benefiting from differentiable programming whose basic idea is treating the neural network as a language instead of a machine learning method. To this end, we recast the vanilla

-means as a novel feedforward neural network in an elegant way. Our contribution is two-fold. On the one hand, the proposed \textit{k}-meansNet is a neural network implementation of the vanilla \textit{k}-means, which enjoys four advantages highly desired, i.e., robustness to initialization, fast inference speed, the capability of handling new coming data, and provable convergence. On the other hand, this work may provide novel insights into differentiable programming. More specifically, most existing differentiable programming works unroll an \textbf{optimizer} as a \textbf{recurrent neural network}, namely, the neural network is employed to solve an existing optimization problem. In contrast, we reformulate the \textbf{objective function} of \textit{k}-means as a \textbf{feedforward neural network}, namely, we employ the neural network to describe a problem. In such a way, we advance the boundary of differentiable programming by treating the neural network as from an alternative optimization approach to the problem formulation. Extensive experimental studies show that our method achieves promising performance comparing with 12 clustering methods on some challenging datasets.
An Explicit Neural Network Construction for Piecewise Constant Function Approximation
We present an explicit construction for feedforward neural network (FNN), which provides a piecewise constant approximation for multivariate functions. The proposed FNN has two hidden layers, where the weights and thresholds are explicitly defined and do not require numerical optimization for training. Unlike most of the existing work on explicit FNN construction, the proposed FNN does not rely on tensor structure in multiple dimensions. Instead, it automatically creates Voronoi tessellation of the domain, based on the given data of the target function, and piecewise constant approximation of the function. This makes the construction more practical for applications. We present both theoretical analysis and numerical examples to demonstrate its properties.
Generalized Canonical Polyadic Tensor Decomposition
Tensor decomposition is a fundamental unsupervised machine learning method in data science, with applications including network analysis and sensor data processing. This work develops a generalized canonical polyadic (GCP) low-rank tensor decomposition that allows other loss functions besides squared error. For instance, we can use logistic loss or Kullback-Leibler divergence, enabling tensor decomposition for binary or count data. We present a variety statistically-motivated loss functions for various scenarios. We provide a generalized framework for computing gradients and handling missing data that enables the use of standard optimization methods for fitting the model. We demonstrate the flexibility of GCP on several real-world examples including interactions in a social network, neural activity in a mouse, and monthly rainfall measurements in India.
• Concentration Based Inference in High Dimensional Generalized Regression Models (I: Statistical Guarantees)
• Privacy Mining from IoT-based Smart Homes
• On the Predictability of non-CGM Diabetes Data for Personalized Recommendation
• Ithemal: Accurate, Portable and Fast Basic Block Throughput Estimation using Deep Neural Networks
• Statistical QoS provisioning for MTC Networks under Finite Blocklength
• Pedestrian Models based on Rational Behaviour
• Very strong evidence in favor of quantum mechanics and against local hidden variables from a Bayesian analysis
• On the real roots of independent domination polynomials
• Machine learning non-local correlations
• The full Schwinger-Dyson tower for random tensor models
• An Approximation Scheme for Quasistationary Distributions of Killed Diffusions
• Proof of the Weak Local Law for Wigner Matrices using Resolvent Expansions
• Position Locationing for Millimeter Wave Systems
• Three Efficient, Low-Complexity Algorithms for Automatic Color Trapping
• Angle Feedback for NOMA Transmission in mmWave Drone Networks
• On the uniqueness of the maximum parsimony tree for data with up to two substitutions: a generalization of the classic Buneman theorem in phylogenetics
• Millimeter-wave Extended NYUSIM Channel Model for Spatial Consistency
• Smoothed Hinge Loss and $\ell^{1}$ Support Vector Machines
• A Tutorial on Clique Problems in Communications and Signal Processing
• Aiming to Know You Better Perhaps Makes Me a More Engaging Dialogue Partner
• Non-asymptotic bounds for sampling algorithms without log-concavity
• Improving Super-Resolution Methods via Incremental Residual Learning
• Satellite Positioning with Large Constellations
• Language Identification in Code-Mixed Data using Multichannel Neural Networks and Context Capture
• Efficient Propagation of Uncertainties in Supply Chains: Time Buckets, L-leap and Multi-Level Monte Carlo
• Geometrical effects on mobility
• Low-Complexity Reconfigurable MIMO for Millimeter Wave Communications
• Faster PET Reconstruction with Non-Smooth Priors by Randomization and Preconditioning
• MobilityMirror: Bias-Adjusted Transportation Datasets
• Signature-based Non-orthogonal Multiple Access (S-NOMA) for Massive Machine-Type Communications in 5G
• Deciding the status of controversial phonemes using frequency distributions; an application to semiconsonants in Spanish
• On Deep Neural Networks for Detecting Heart Disease
• Statistical Neurodynamics of Deep Networks: Geometry of Signal Spaces
• Fisher Information and Natural Gradient Learning of Random Deep Networks
• Optimizing the MIMO Cellular Downlink: Multiplexing, Diversity, or Interference Nulling?
• Intersections, circuits, and colorability of line segments
• Efficient sparse Hessian based algorithms for the clustered lasso problem
• Can 3D Pose be Learned from 2D Projections Alone?
• The effect on the spectral radius of r-graphs by grafting or contracting edges
• Identifying High-Quality Chinese News Comments Based on Multi-Target Text Matching Model
• Robust Designs via Geometric Programming
• New Bounds for Energy Complexity of Boolean Functions
• Eulerian edge refinements, geodesics, billiards and sphere coloring
• Coarse-to-Fine Annotation Enrichment for Semantic Segmentation Learning
• A Characterwise Windowed Approach to Hebrew Morphological Segmentation
• Don’t Use Large Mini-Batches, Use Local SGD
• Approximating Poker Probabilities with Deep Learning
• A multistate model for early decision making in oncology
• On the number of Hadamard matrices via anti-concentration
• Mean-field approximation, convex hierarchies, and the optimality of correlation rounding: a unified perspective
• Hierarchical Neural Network for Extracting Knowledgeable Snippets and Documents
• Reducing Gender Bias in Abusive Language Detection
• Semidefinite Relaxation Based Blind Equalization using Constant Modulus Criterion
• Finding Good Representations of Emotions for Text Classification
• Environment Overwhelms both Nature and Nurture in a Model Spin Glass
• Controversy Rules – Discovering Regions Where Classifiers (Dis-)Agree Exceptionally
• Improving Matching Models with Contextualized Word Representations for Multi-turn Response Selection in Retrieval-based Chatbots
• Stability of regime-switching processes under perturbation of transition rate matrices
• Analysis of Network Lasso For Semi-Supervised Regression
• Weak convergence of Euler-Maruyama’s approximation for SDEs under integrability condition
• Distributed Big-Data Optimization via Block-Iterative Gradient Tracking
• Escaping from Collapsing Modes in a Constrained Space
• On an improvement of LASSO by scaling
• Exponential synchronization of the high-dimensional Kuramoto model with identical oscillators under digraphs
• Linearity versus non-linearity in high frequency multilevel wind time series measured in urban areas
• Block Sequential Decoding Techniques for Polar Subcodes
• A Deep Neural Network for Pixel-Level Electromagnetic Particle Identification in the MicroBooNE Liquid Argon Time Projection Chamber
• Learning to Support: Exploiting Structure Information in Support Sets for One-Shot Learning
• Deep Adaptive Temporal Pooling for Activity Recognition
• CentralNet: a Multilayer Approach for Multimodal Fusion
• A syllable based model for handwriting recognition
• On complex Gaussian random fields, Gaussian quadratic forms and sample distance multivariance
• DeepCorr: Strong Flow Correlation Attacks on Tor Using Deep Learning
• Comparison of Dynamic Treatment Regimes with An Ordinal Outcome
• Clustering and Labelling Auction Fraud Data
• The Gap of Semantic Parsing: A Survey on Automatic Math Word Problem Solvers
• A counterexample to a conjecture of Larman and Rogers on sets avoiding distance 1
• Deep Association Learning for Unsupervised Video Person Re-identification
• Hybrid ASP-based Approach to Pattern Mining
• Doubly Robust Regression Analysis for Data Fusion
• Learning Sentiment Memories for Sentiment Modification without Parallel Data
• Recovering Hidden Components in Multimodal Data with Composite Diffusion Operators
• Predicting Musical Sophistication from Music Listening Behaviors: A Preliminary Study
• The Scaled Uniform Model Revisited
• Multi-Grained-Attention Gated Convolutional Neural Networks for Sentence Classification
• Semi-Trained Memristive Crossbar Computing Engine with In-Situ Learning Accelerator
• Multidomain Document Layout Understanding using Few Shot Object Detection
• On Reachability Mixed Arborescence Packing
• Improved bounds for the RIP of Subsampled Circulant matrices
• A method for automatic forensic facial reconstruction based on dense statistics of soft tissue thickness
• Deep Extrofitting: Specialization and Generalization of Expansional Retrofitting Word Vectors using Semantic Lexicons
• Scenario-based Risk Evaluation
• Integrative Probabilistic Short-term Prediction and Uncertainty Quantification of Wind Power Generation
• Multi-Branch Siamese Networks with Online Selection for Object Tracking
• Gromov’s waist of non-radial Gaussian measures and radial non-Gaussian measures
• Long monotone trails in random edge-labelings of random graphs
• Neural Named Entity Recognition from Subword Units
• Multi-Array 5G V2V Relative Positioning: Performance Bounds
• Learning When to Concentrate or Divert Attention: Self-Adaptive Attention Temperature for Neural Machine Translation
• Convergence of Cubic Regularization for Nonconvex Optimization under KL Property
• Dynamic Self-Attention : Computing Attention over Words Dynamically for Sentence Embedding
• A Note on Inexact Condition for Cubic Regularized Newton’s Method
• Sensitivity Analysis using Approximate Moment Condition Models
• Domino shuffling height process and its hydrodynamic limit
• Exponentiated Inverse Power Lindley Distribution and its Applications
• Manipulating Attributes of Natural Scenes via Hallucination
• Blind Phaseless Short-Time Fourier Transform Recovery
• Joint Coarse-And-Fine Reasoning for Deep Optical Flow
• Uncertainty in finite planes
• Deep Boosted Regression for MR to CT Synthesis
• Bayesian Estimation of Sparse Spiked Covariance Matrices in High Dimensions
• Hall effect in 2D systems with hopping transport and strong disorder
• New lower bound on the Shannon capacity of C7 from circular graphs
• 3D Topology Optimization using Convolutional Neural Networks
• Robust Spatial Extent Inference with a Semiparametric Bootstrap Joint Testing Procedure
• Stacked Pooling: Improving Crowd Counting by Boosting Scale Invariance
• Cross Subspace Alignment and the Asymptotic Capacity of $X$-Secure $T$-Private Information Retrieval
• Homological properties of contractible transformations of graphs
Like this:
Like Loading...